According to a data quality survey by Monte Carlo, poor data quality costs businesses 31% of their revenue on average.
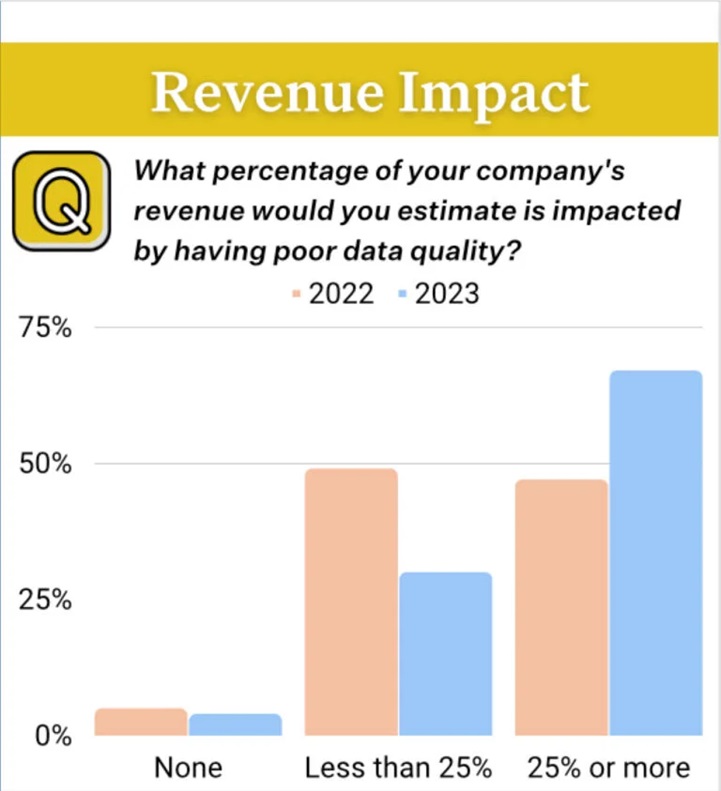 [
[The same survey also indicates that it takes businesses more than half a day to evaluate the quality of their data and over four hours to fix an issue once it is discovered.
Since data is essential for informed decision-making, maintaining its quality is a top priority for businesses. However, with massive amounts of data available at their disposal, how can organizations determine which data to clean first for the maximum impact? The answer is simple: follow the data use case impact approach. What is this approach and how businesses can utilize it to prioritize their data cleaning needs, let’s understand through this blog.
Deciding Which Business Data To Prioritize: A Simple Approach To Follow
Understand use cases and requirements for your business at its current stage
The best way to prioritize the data for cleaning is to consider the use case impact. This means identifying the decisions that are crucial at the existing stage of your business and the corresponding data that would be needed (considering these will have the biggest impact) to make these decisions. Once this data is identified, you can prioritize the data-cleaning task accordingly.
For example, a mid-size business at its growing stage might have the following three most crucial use cases:
- Maintaining the success of a well-performing product line
- Turning around an underperforming product line
- Launching a new product line and managing its success
Now, if the primary goal of that business is to sustain revenue and growth, it might prioritize cleaning the data related to its well-performing product line. On the other hand, if the primary goal is to improve overall profitability, the company should prioritize the data related to underperforming product lines for cleaning. Further, if the focus is on future growth, then the cleansing of data related to the new product launch must be the top priority.
Identify high-impact data and the most critical fields for each use case
Once you have identified your most important use cases, you can then identify the data and critical data fields that will impact that use case the most.
For example, for the above-mentioned use cases, the high-impact data can be the following:
- High-impact data for a well-performing product line
- Sales data (product sold, quantity, price, etc.)
- Customer data (contact details, demographics, etc.)
- Product performance data (customer reviews, ratings, number of product returns, etc.)
- High-impact data for an underperforming product line
- Market research data (market trends, customer needs, and competitor performance)
- Customer behavior data (how they interacted with the product, customer churn & usage data, product reviews, etc.)
- Cost data (overall cost involved in the production, marketing, and distribution of the product)
- High-impact data for product line to be launched
- Market research data
- Customer segmentation data
- Cost data (involved in production, marketing, and distribution of the product)
Now, prioritize cleaning the data that is most important for the decisions you want to make first. For example, if you need data to make decisions about marketing campaigns, you should prioritize cleaning your customer data.
Evaluate the current dataset and identify the most critical errors to address first
Once you have the database you need to clean, you need to identify the level of errors it has, such as duplicate entries, outliers, missing values, inaccurate details, and inconsistent formatting. Now after identifying the errors, you can categorize them based on their severity and impact on your use cases. For example, if you are using your data to train an ML or AI model, missing values and outliers can be problematic. So, you would want to address those issues first.
Create a data cleansing priority matrix to map data issues to use case importance
A data priority matrix can help business users prioritize which errors to fix first by mapping the severity of each data issue to its solving complexity level and the importance of the use case. This gives users a clear overview of all the data errors, their criticality, and their difficulty to fix.
The severity of each data issue can be rated on a scale of 1 to 5, with 1 being the least severe and 5 being the most severe. Once you have rated the severity of each data issue for each use case, you can calculate the overall priority for each data issue by multiplying the use case importance by the severity rating.
The higher the overall priority, the more important it is to address the data issue at the earliest.
Example of data cleansing priority matrix:
| Use case importance | Data issue | Severity | Overall priority |
| Very critical (5) | Missing email addresses | 5 | 25 |
| Important (3) | Duplicate addresses | 3 | 9 |
| Less critical (1) | Inconsistent formatting of customer names | 1 | 1 |
Identify issues that can be fixed with simple changes and do those first (high importance, simple issue)
There will be some data issues in your database that will be of high importance and easy to fix. For instance, duplicate values or typing mistakes. Ideally, you should prioritize to clean such issues first. By focusing on the important and easy-to-fix data cleaning tasks first, you can make a significant improvement in the quality of your data without having to spend a lot of time or resources.
To fix such issues, you can use various tools and techniques, such as spreadsheet programs that can be used to fix duplicate entries, and similarly, regular expressions can be used to fix typing errors.
Start fixing high-importance, high-criticality issues next
Prioritizing critically important and easy-to-fix errors is simple for businesses. But at the same, data cleaning prioritization of critical and difficult-to-solve issues is also important. To clean or fix such issues, businesses need to allocate more resources or a team of experts who can identify these errors easily and address them quickly. Along with the expert resources, advanced tools and techniques are also required to resolve such errors.
For example, fixing the issue of missing email addresses in customer databases is both critical and time-consuming. Only expert resources can meticulously extract the missing information from reliable sources, add it to your database, and verify it for accuracy & relevance. To address this issue, businesses can either hire experienced professionals in-house or outsource data enrichment services to experts.
Re-evaluate priorities periodically based on new data/shifts in use cases
Businesses need to regularly track how their data quality and business needs change over time to identify emerging data issues that need to be addressed first. For example, a retail company might need to prioritize cleaning its customer data to improve its targeted marketing campaigns. As the company grows and expands into new markets, its customer data will become more complex and require more frequent cleaning.
Based on new data insights and evolving business needs, organizations can adjust their data cleaning priorities and fine-tune their strategies consistently to ensure their data remains clean, accurate, and updated, aligning with their business goals.
Key Takeaway
Prioritizing data cleaning based on use case impact is essential to improve & maximize the quality & utility of the data for various business needs. By focusing on cleaning the data that is most important for specific use cases, organizations can improve the accuracy and reliability of their insights, make better decisions, and achieve their business goals more effectively.
To efficiently follow the above-mentioned approach for prioritizing data cleaning needs for their businesses, organizations need to ensure that they have access to expert resources and advanced tools & techniques. If not, then it is better for businesses to outsource data scrubbing services to a reliable third-party provider that has a dedicated team of professionals and state-of-the-art infrastructure to enhance the quality of your critical datasets.
Jessica Watson is a Content Strategist, currently engaged at Data-Entry-India.com- a globally renowned data entry and management company -for over five years. She spends most of her time reading and writing about transformative data solutions, helping businesses to tap into their data assets and make the most out of them. So far, she has written over 2000 articles on various data functions, including data entry, data processing, data management, data hygiene, and other related topics. Besides this, she also writes about eCommerce data solutions, helping businesses uncover rich insights and stay afloat amidst the transforming market landscapes. Twitter
Cleaning data stock image by SvetaZi/Shutterstock